 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Semantic Profiles into Knowledge Graph for Recommender Systems Using Large Language Models
Jan 13, 2026Rich and informative profiling to capture user preferences is essential for improving recommendation quality. However, there is still no consensus on how best to construct and utilize such profiles. To address this, we revisit recent profiling-based approaches in recommender systems along four dimensions: 1) knowledge base, 2) preference indicator, 3) impact range, and 4) subject. We argue that large language models (LLMs) are effective at extracting compressed rationales from diverse knowledge sources, while knowledge graphs (KGs) are better suited for propagating these profiles to extend their reach. Building on this insight, we propose a new recommendation model, called SPiKE. SPiKE consists of three core components: i) Entity profile generation, which uses LLMs to generate semantic profiles for all KG entities; ii) Profile-aware KG aggregation, which integrates these profiles into the KG; and iii) Pairwise profile preference matching, which aligns LLM- and KG-based representations during training. In experiments, we demonstrate that SPiKE consistently outperforms state-of-the-art KG- and LLM-based recommenders in real-world settings.
Understanding Bias in Perceiving Dimensionality Reduction Projections
Jul 28, 2025Selecting the dimensionality reduction technique that faithfully represents the structure is essential for reliable visual communication and analytics. In reality, however, practitioners favor projections for other attractions, such as aesthetics and visual saliency, over the projection's structural faithfulness, a bias we define as visual interestingness. In this research, we conduct a user study that (1) verifies the existence of such bias and (2) explains why the bias exists. Our study suggests that visual interestingness biases practitioners' preferences when selecting projections for analysis, and this bias intensifies with color-encoded labels and shorter exposure time. Based on our findings, we discuss strategies to mitigate bias in perceiving and interpreting DR projections.
Dataset-Adaptive Dimensionality Reduction
Jul 16, 2025



Selecting the appropriate dimensionality reduction (DR) technique and determining its optimal hyperparameter settings that maximize the accuracy of the output projections typically involves extensive trial and error, often resulting in unnecessary computational overhead. To address this challenge, we propose a dataset-adaptive approach to DR optimization guided by structural complexity metrics. These metrics quantify the intrinsic complexity of a dataset, predicting whether higher-dimensional spaces are necessary to represent it accurately. Since complex datasets are often inaccurately represented in two-dimensional projections, leveraging these metrics enables us to predict the maximum achievable accuracy of DR techniques for a given dataset, eliminating redundant trials in optimizing DR. We introduce the design and theoretical foundations of these structural complexity metrics. We quantitatively verify that our metrics effectively approximate the ground truth complexity of datasets and confirm their suitability for guiding dataset-adaptive DR workflow. Finally, we empirically show that our dataset-adaptive workflow significantly enhances the efficiency of DR optimization without compromising accuracy.
Stop Misusing t-SNE and UMAP for Visual Analytics
Jun 10, 2025



Misuses of t-SNE and UMAP in visual analytics have become increasingly common. For example, although t-SNE and UMAP projections often do not faithfully reflect true distances between clusters, practitioners frequently use them to investigate inter-cluster relationships. In this paper, we bring this issue to the surface and comprehensively investigate why such misuse occurs and how to prevent it. We conduct a literature review of 114 papers to verify the prevalence of the misuse and analyze the reasonings behind it. We then execute an interview study to uncover practitioners' implicit motivations for using these techniques -- rationales often undisclosed in the literature. Our findings indicate that misuse of t-SNE and UMAP primarily stems from limited discourse on their appropriate use in visual analytics. We conclude by proposing future directions and concrete action items to promote more reasonable use of DR.
Data Therapist: Eliciting Domain Knowledge from Subject Matter Experts Using Large Language Models
May 01, 2025Effective data visualization requires not only technical proficiency but also a deep understanding of the domain-specific context in which data exists. This context often includes tacit knowledge about data provenance, quality, and intended use, which is rarely explicit in the dataset itself. We present the Data Therapist, a web-based tool that helps domain experts externalize this implicit knowledge through a mixed-initiative process combining iterative Q&A with interactive annotation. Powered by a large language model, the system analyzes user-supplied datasets, prompts users with targeted questions, and allows annotation at varying levels of granularity. The resulting structured knowledge base can inform both human and automated visualization design. We evaluated the tool in a qualitative study involving expert pairs from Molecular Biology, Accounting, Political Science, and Usable Security. The study revealed recurring patterns in how experts reason about their data and highlights areas where AI support can improve visualization design.
Real-time Calibration Model for Low-cost Sensor in Fine-grained Time series
Dec 28, 2024



Precise measurements from sensors are crucial, but data is usually collected from low-cost, low-tech systems, which are often inaccurate. Thus, they require further calibrations. To that end, we first identify three requirements for effective calibration under practical low-tech sensor conditions. Based on the requirements, we develop a model called TESLA, Transformer for effective sensor calibration utilizing logarithmic-binned attention. TESLA uses a high-performance deep learning model, Transformers, to calibrate and capture non-linear components. At its core, it employs logarithmic binning to minimize attention complexity. TESLA achieves consistent real-time calibration, even with longer sequences and finer-grained time series in hardware-constrained systems. Experiments show that TESLA outperforms existing novel deep learning and newly crafted linear models in accuracy, calibration speed, and energy efficiency.
SANVis: Visual Analytics for Understanding Self-Attention Networks
Sep 13, 2019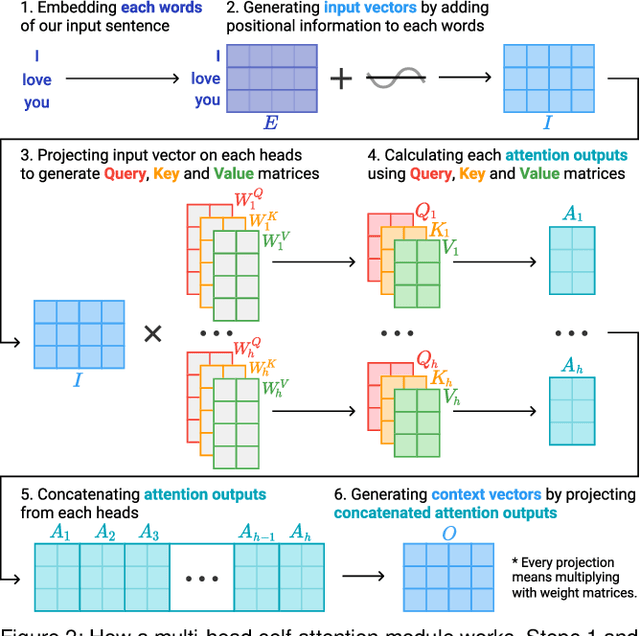
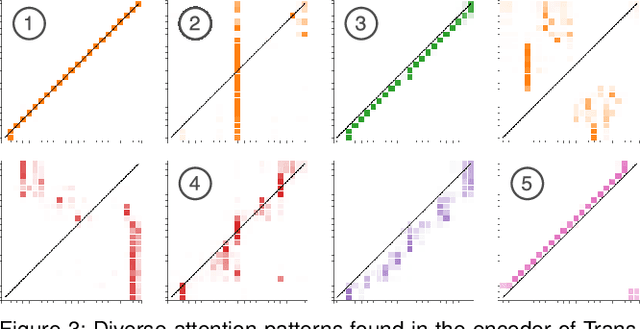
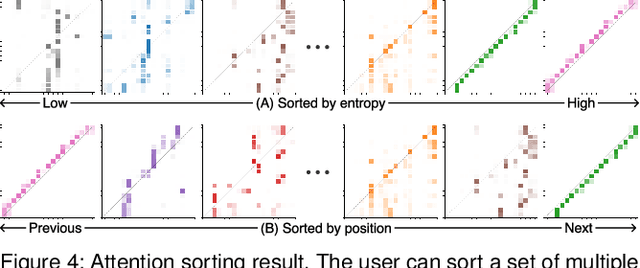
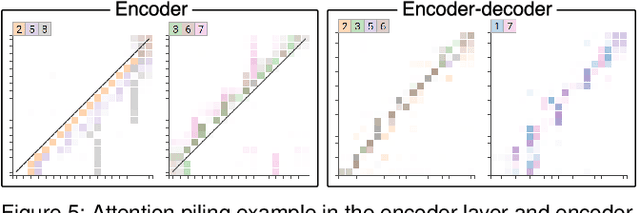
Attention networks, a deep neural network architecture inspired by humans' attention mechanism, have seen significant success in image captioning, machine translation, and many other applications. Recently, they have been further evolved into an advanced approach called multi-head self-attention networks, which can encode a set of input vectors, e.g., word vectors in a sentence, into another set of vectors. Such encoding aims at simultaneously capturing diverse syntactic and semantic features within a set, each of which corresponds to a particular attention head, forming altogether multi-head attention. Meanwhile, the increased model complexity prevents users from easily understanding and manipulating the inner workings of models. To tackle the challenges, we present a visual analytics system called SANVis, which helps users understand the behaviors and the characteristics of multi-head self-attention networks. Using a state-of-the-art self-attention model called Transformer, we demonstrate usage scenarios of SANVis in machine translation tasks. Our system is available at http://short.sanvis.org